If you’ve shipped an agentic system in the last eighteen months, you’ve probably hit the same wall: improvements arrive as a series of prompt edits and tool tweaks that no one can audit, reproduce, or roll back. The system gets better, then worse, then better again, and no one can tell you why. That’s not engineering. That’s accretion.
There’s a name for the alternative now. Harness engineering — the discipline of treating everything around the LLM call as the editable, versioned, falsifiable surface where engineering effort accumulates — was formalized in Lin et al., Agentic Harness Engineering (arXiv:2604.25850, 2026). I’ve spent the last six weeks adapting it to PACCA, a production-targeted multi-agent system for healthcare prior authorization. The methodology shift matters more than the use case, so I’ll focus on what generalizes.
The harness is the lever
The base model is fixed. You don’t tune Claude or GPT. What you do tune — prompts, tools, middleware, memory layers, sub-agent topology, retrieval collections — is the harness. Lin et al. decompose this into seven component types and mount each at a fixed file path so changes are one-file diffs with clean rollback granularity. PACCA adds four healthcare-specific surfaces on top: an escalation tree, dual RAG collections, a prompt registry, and an audit schema. Eleven editable mount points, each with one owner.
The first practical consequence: when a behavioral change ships, you can point to exactly one file. When the eval suite regresses, you can revert exactly one file. The diff is signal, not noise. This sounds like hygiene. It’s actually the precondition for everything else.
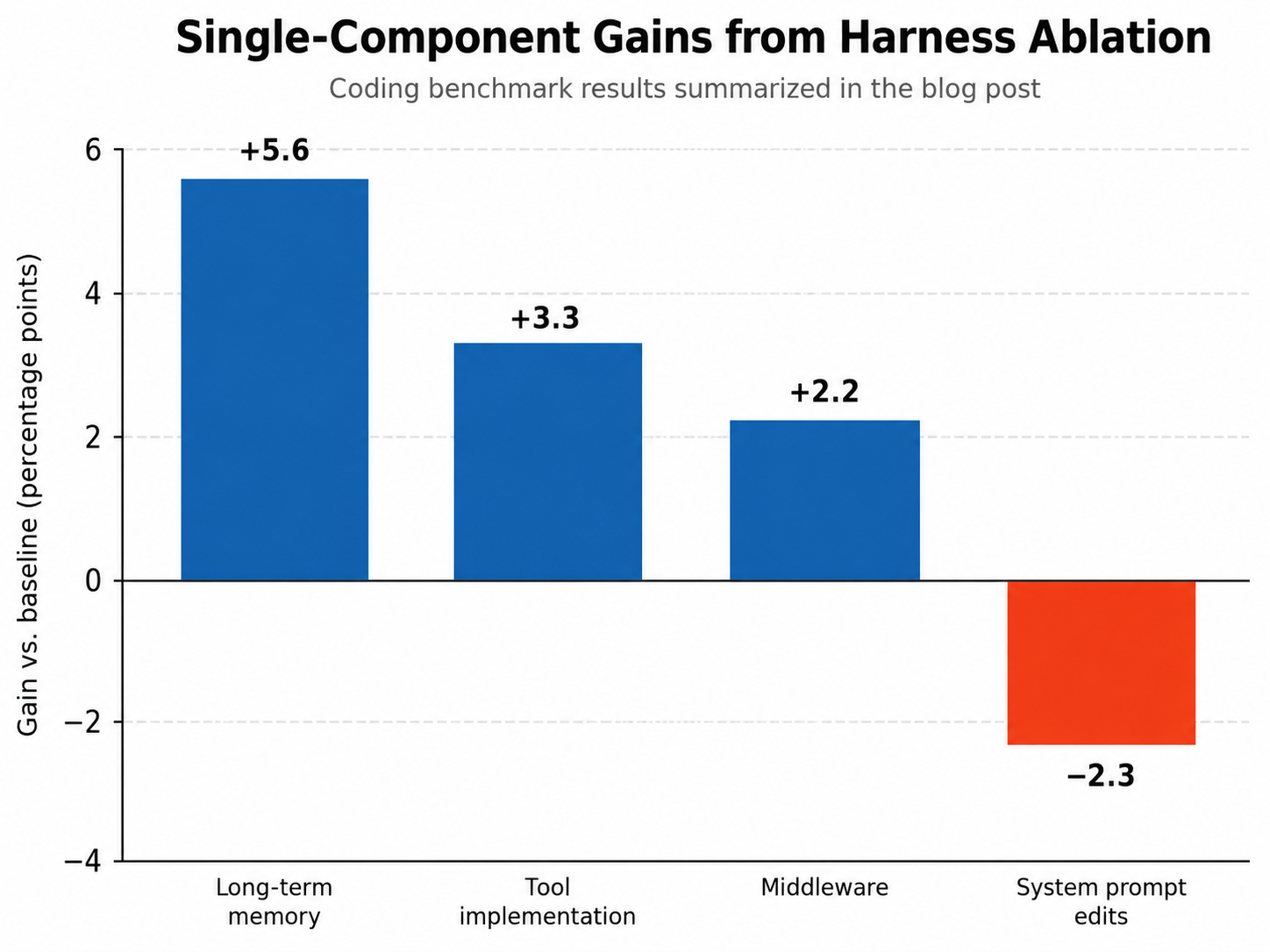
The findings that should change how you build
The paper’s component ablation table is the most useful empirical contribution of 2026 so far. On a coding benchmark, single-component gains looked like this:
- Long-term memory alone: +5.6 pp
- Tool implementation alone: +3.3 pp
- Middleware alone: +2.2 pp
- System prompt edits alone: −2.3 pp (yes, negative)
Three things to internalize. First, the biggest single lever is the layer most teams don’t have — a human-readable, git-versioned memory file that rides in the prompt context on every request. This is distinct from vector-store retrieval; it’s the dozen or so cross-cutting lessons that always fire because they always ship. Second, tools and middleware carry most of the remaining gain. Push behaviors into the tool surface, not into prose. Third, system prompt edits in isolation tend to regress. The dominant industry practice — iterate on the system prompt and hope — is empirically the worst single intervention.
The lesson is not “don’t edit prompts.” The lesson is: pair structural changes with prompt changes, and never ship a prompt edit in isolation without an eval that would catch its regression.
Middleware is the missing tier
If you’ve never thought of agent middleware as a first-class component, you’re in good company — most frameworks expose orchestrators and tools but quietly leave middleware to ad-hoc callbacks. Lin et al.’s middleware tier intercepts the model’s tool calls and emits targeted hints into the next model turn when it detects cross-step risk patterns. Crucially, hints go into model context via a BeforeModelHook, not appended to tool output, because the paper’s iteration-8 result shows hints in tool output are reliably ignored on subsequent turns. Where you inject the signal matters as much as the signal itself.
In PACCA we ship five middleware: a guideline-retrieval check, a rubric-coverage validator, a confidence-calibration check against precedent base rates, a precedent-consistency flag, and — most importantly — an escalation guard implemented as a state machine, not a prompt rule. Once a case escalates to the Medical Director, the Frontline agent cannot retroactively auto-approve. Try enforcing that with a prompt rule across long contexts and you’ll lose. Enforce it in middleware and you’ve made the failure structurally impossible. In healthcare that distinction is the difference between an audit finding and a patient safety event.
Manifest discipline: ship falsifiable contracts
Here’s the part that separates production engineering from prototyping. Every behavioral harness change ships with a manifest entry — a JSON record that names the failure pattern, the root cause, the predicted fixes, the predicted regressions, and the constraint level (which of the eleven mount points was edited). The next evaluation round produces a verdict file: did the fixes land? did the predicted regressions appear? did unpredicted ones?
The empirical kicker, also from the paper: self-prediction of fixes runs about 5× random precision and recall. Self-prediction of regressions is barely 2× random. The model predicting its own future failures is essentially noise. The evaluation suite, not the manifest, is the safety net. This is why manifest discipline only works alongside an honest benchmark with k≥2 rollouts per case and infrastructure failures counted as failures, not silently dropped.
PACCA’s manifest is governed by a JSON Schema 2020-12 spec checked into harness/manifests/. Every chg-N: commit on the agent layer requires either a manifest entry or an explicit non-behavioral opt-out. An append-only DECISIONS.md accumulates every entry plus its verdict. Two things result: a public engineering record that distinguishes iteration from accretion, and an audit artifact that compliance work can build on directly. In a regulated domain, the second is not optional.
What this gives you
Three things, in order of importance:
- A reference frame. Without a tagged baseline (
harness-iter-0) and structured trajectory logs, every claim of improvement is vibes. - A change unit. Without file-level component decoupling, you can’t isolate signal from refactor noise — and you’ll keep shipping prompt changes that quietly regress.
- A falsifiable contract. Without manifests and verdicts, you can’t tell whether you’re iterating or wandering.
None of this requires a research lab. The infrastructure is a JSON Schema, a Markdown file per agent, five middleware classes, and the discipline to write one manifest entry per behavioral commit. PACCA’s v2.3 cycle targets six tagged iterations over twelve weeks. The cumulative pass@1 improvement we’re predicting is +3 to +8 percentage points — modest by demo-day standards, defensible by audit standards. That’s the trade I’d make every time in production.
If you’re building agentic systems and your engineering velocity feels like it’s slowing rather than compounding, the diagnosis is usually the same: you’re editing prompts, not engineering a harness. Fix the substrate. The rest follows.